AWS Distro for OpenTelemetry
Getting Started with Advanced Sampling using AWS Distro for OpenTelemetry
Getting Started with Advanced Sampling using AWS Distro for OpenTelemetry
In this guide, we will provide basic information about advanced sampling with the Group By Trace and Tail Sampling processor using ADOT and show an example of how you can add it to your own existing configuration. We will also show how to scale with advanced sampling by adding a load balancing component in front of multiple collector instances.
IMPORTANT: Advanced sampling with the Group By Trace and Tail Sampling processors is not available in the ADOT Lambda Layers. This is due to the batching requirement in Lambda Layers using the batch span processor.
What is Advanced Sampling
Advanced sampling refers to the strategy where we use the Group By Trace processor and Tail Sampling processor in order to making sampling decisions based on set policies regarding the spans of a trace. Advanced sampling helps you control the volume of traces ingested into AWS X-Ray or other backends which results in reduced costs from only exporting the traces that are deemed important.
What is the Group by Trace Processor
The Group By Trace processor gathers all of the spans of a trace and waits a pre-defined time before moving them to the next processor. This component is usually used before the tail sampling processor to guarantee that all the spans belonging to a same trace are processed together.
What is the Tail Sampling Processor
The Tail Sampling processor samples traces based on user-defined policies. For this component to make the most accurate sampling decision, it needs all spans belonging to a trace to be processed together in the same backend.
Best practices for Advanced Sampling
- In order to achieve the desired results when using the Group by Trace and Tail Sampling processors, do not use a Batch processor before these components in a pipeline. Using a Batch processor before these components might separate spans belonging to the same trace. It is important to pay attention to this detail because these components will try to group all the spans belonging to a trace when processing. In the case of the Tail Sampling processor, this will allow for a sampling decision to affect all spans of a trace, creating a full picture of the trace in case it is sampled. A Batch processor immediately after these components does not cause any problems and is recommended to properly pre-process data for subsequent exporters.
- You have to tune the
wait_durationparameter of the Group by Trace processor to be greater than or equal to the maximum expected latency of a trace in your system. Also, be sure to include a grace period for network latency between an application and collector. Again, this will guarantee that spans of a same trace are processed in the same batch. - We recommend to limit the number of traces that should be kept in memory by implementing the
num_tracesconfiguration option of the Group by Trace processor. However, it should be noted that this processor will drop the oldest trace in case thenum_traceslimit is exceeded. wait_durationandnum_tracesshould be scaled to consider the expected traffic in the monitored applications. It is highly recommended that you monitor theotelcol_processor_groupbytrace_traces_evictedmetric from the collector self telemetry. If the value in the metric is greater than zero, that means that the collector is receiving more traffic than it can handle and you should increase thenum_tracesaccordingly.
How can I start using Advanced Sampling?
The first step to advanced sampling is to make sure that traces are being exported to the ADOT Collector instance. If needed for testing purposes, you can use our line of sample apps that are instrumented with the OpenTelemetry SDK to produce traces. Please follow the directions in the sample app’s README for instructions on how to run the app locally or build/run a local image.
The next step is to add the Group By Trace and Tail Sampling processors to your ADOT Collector configuration. A sample configuration looks like the following:
1processors:2 groupbytrace:3 wait_duration: 10s4 num_traces: 20000 # Double the max expected traffic (2 * 10 * 1000 requests per second)5 tail_sampling:6 decision_wait: 1s # This value should be smaller than wait_duration7 policies:8 - ..... # Applicable policies9 batch/tracesampling:10 timeout: 0s # No need to wait more since this will happen in previous processors11 send_batch_max_size: 8196 # This will still allow us to limit the size of the batches sent to subsequent exporters12
13service:14 pipelines:15 traces/tailsampling:16 receivers: [otlp]17 processors: [groupbytrace, tail_sampling, batch/tracesampling]18 exporters: [awsxray]As an example of how to determine the values for the Group By Trace and Tail Sampling processors, we must analyze certain characteristics of our application as mentioned above. Let's say the maximum expected latency for a request in your application is 10s and the maximum traffic in number of requests per second that your application can have is 1000 requests per second. This means that the wait_duration should be set to 10s and num_traces should be set to at least 10000 (10 * 1000 requests per second) as displayed in this sample configuration.
To see the full set of policy options available and other configuration options for the Tail Sampling processor please refer to its README. To see more configuration options for the Group By Trace processor, please refer to its README.
Scaling with Advanced Sampling
After adding the Group By Trace and Tail Sampling processors to your ADOT Collector, you now have advanced sampling and can experience the benefits of reducing ingests into AWS X-Ray. However, many current architectures involve multiple sets or replicas of collector instances to distribute the load and resource usage. The problem with adding advanced sampling to a system of multiple collectors is that spans of the same trace must be processed in the same collector instance. If not, the sampling decision would be inaccurate as not all of the spans are used when it comes time to process and spans sent to a different collector would not retain the sampling decision if it was already made by the Tail Sampling processor.
To solve this, one could follow the Gateway deployment pattern and add a collector that has a Load Balancing Exporter in front of the Group By Trace and Tail Sampling processors. This way we can horizontally scale collector instances with advanced sampling by distributing the telemetry data for sampling.
What is the Load Balancing Exporter?
The Load Balancing Exporter consistently sends traces and logs to the same backend depending on a configurable routing key. The default routing key is traceID and so this component would be used to make sure that spans of the same trace are sent to the same backend, which in this case, is a collector instance. In order to communicate with these backends, different resolver options are available such as static, dns, and k8s resolvers for hostnames. For more configuration options available to the Load Balancing Exporter, please refer to its README.
End-to-End Path for Scaled Advanced Sampling
The below image shows an example of scaling by adding a gateway collector with a Load Balancing Exporter. This gateway collector then uses static hostnames to send spans to 3 collector instances with advanced sampling:
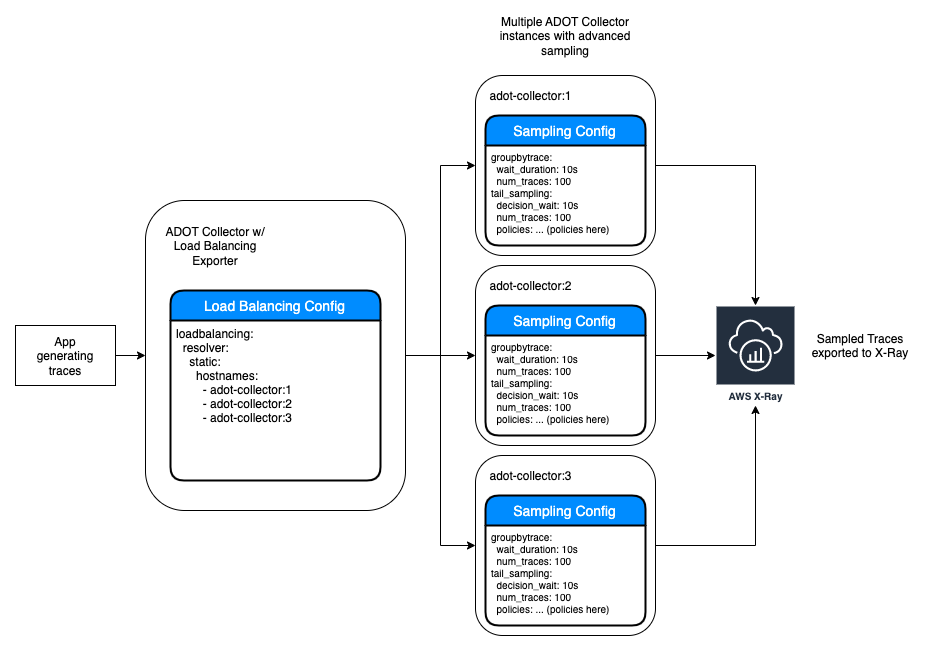
How could I deploy the advanced sampling with scalability?
There are a number of ways you could scale out this layer of multiple ADOT Collectors with advanced sampling. One way is to use the EKS Add-on to deploy a cluster of ADOT Collector instances. Another way is to use ECS to deploy multiple tasks of the ADOT Collector. Overall, feel free to deploy the layer whichever way that suits your needs as long as the individual ADOT Collector instances can be resolved by the Load Balancing Exporter in the gateway collector by using the static, dns, or k8s resolver.
Conclusion
Using this pattern to achieve advanced sampling with horizontally-scaled collectors is a great way to reduce the resource usage between multiple collectors and support the higher throughput that comes with a bigger architecture.